|
Acceleration Strategies in Generalized Belief Propagation |
|
Shengyong Chen, Senior Member, IEEE,?and Zhongjie Wang |
Abstract?/span>Generalized Belief Propagation is a popular algorithm to perform inference on large scale Markov Random Fields (MRFs) networks. This paper proposes the method of accelerated generalized belief propagation (AGBP) with three strategies to reduce the computational effort. Firstly, a min-sum messaging scheme and a caching technique are used to improve the accessibility. Secondly, a direction set method is used to reduce the complexity of computing clique messages from quartic to cubic. Finally, a coarse-to-fine hierarchical state space reduction method is presented to decrease redundant states. The results show that a combination of these strategies can greatly accelerate the inference process in large scale MRFs. For common stereo matching, it results in a speed-up of about 200 times.
Index Terms?/span>Markov random fields, inference, high order, pattern analysis, computer vision, accelerated generalized belief propagation (AGBP)
I. INTRODUCTION
MARKOV Random Fields (MRFs) is a widely used graphical model in various disciplines such as statistical learning, pattern analysis, coding and decoding, and image understanding. Many applications in these areas can be found in industrial informatics [1-3]. The inference of MRFs has received profound research [4][5]. Among heterogeneous approaches, Belief Propagation (BP) is one of the most superior methods [6]. In order to acquire marginal posterior probabilities, it uses a message passing strategy to iteratively update beliefs and messages for every variable. In graphical models without loops, this approach had proven to provide the exact marginal posterior probabilities, whereas in graphical models with massive loops, as in the grid-like MRFs, the convergence problem becomes more difficult. To accelerate convergence, many approaches have been proposed and some significant progress has been achieved. However, due to the slow convergence of BP in graphical models with loops, the interest of BP has decreased. On the other hand, generalized belief propagation (GBP) proposed by Yedidia et al. [7] with its better convergence property compared to BP has recently received a large attention.
GBP can be considered as an extension of BP. It is also an instance of cluster variation methods. As described in the literature, BP can only converge to a stationary point of Bethe free energy, while GBP can converge to a stationary point of Kikuchi free energy which is a more stable approximation than Bethe free energy [8], which leads to an improved convergence property. Despite its good convergence, GBP requires a large computational effort. Without any optimization, the canonical version of GBP takes a quartic temporal complexity, while the fast version of BP in [9] reaches linear complexity. This severely restricts its applicability in the inference of low order graphical models, and obviously prevents the application of GBP for more complicated problems [10][11].
This paper proposes an approach to accelerate GBP, which is called Accelerated Generalized Belief Propagation (AGBP) in the following. This paper focuses on the problem of inference in large-scale grid-like MRFs. The term ‘large-scale?referred here to the large number of variables but also to the large state space for each node. To make GBP more efficient in this kind of graphical models, Petersen et al. [11] propose two acceleration methods to improve the performance of GBP. The first one is a caching strategy. By caching some pre-computed variables, many redundant computations can be avoided. The first acceleration method proposed in this paper adopts this method, and achieves a similar acceleration rate. The second acceleration method proposed in [11] is to convert a searching problem on a grid into a linear searching problem. Since the converted linear searching problem should be monotonous, such a method is probably going into a local minimum and the acceleration rate is largely influenced by the size of the square. Compared with previous approaches, the proposed AGBP promises a great acceleration. Strategies are explained in this paper. First, a min-sum messaging scheme and a caching technique are used to improve the accessibility. Second, a direction set method is introduced into the pair-wise message computation stage which decreases the temporal complexity from quartic to cubic. Finally, a strategy of hierarchical state space reduction is proposed to significantly reduce the redundant states in every hierarchical level which can further decrease the quantity of computations.
II. Problem Formulation
This paper takes the example of GBP formulation for a stereo vision system where stereo matching is an inference problem in MRFs for depth map estimation [12][13]. This can be posed as an energy minimization problem. The corresponding energy function used here is the most conspicuous one which is defined as
![]() ?(1)
?(1)
where N is the four-connected neighborhood set, D denotes the data cost for assigning a label fp to a pixel p, and V denotes the pairwise cost for labeling between two neighbor pixels p and q. The pairwise cost can induce close pixels to have same labels, which makes the result smooth.
The data cost is calculated by a truncated linear model, defined as
![]() ? ?2)
? ?2)
where l is the cost weight which determines the portion of energy that data cost possesses in the whole energy, T represents the truncating value, and IcL(p) and IcR(p) represent the intensity values of pixel p of channel c in the left and right images, respectively. It can improve the final results to some degree as observed from our practical experience.
The pairwise cost is defined as
![]() ?
(3)
?
(3)
where K is the truncating value. The pairwise cost smoothes the result but also preserves discontinuity, since it can prevent the edges of objects from over smoothing.
The energy function defined in (1) can be considered as a description of the scene. Here an assumption is made that the minimum of (1) is always matched with the correct scene structure, which is represented by the depth information in stereo matching. In literature, to make the condition assumption more accurate, a rather complex energy function should be employed. However, to simplify the presentation and to be consistent and comparable with other methods, the dualistic energy function as (1) is used in this paper.
III. Message Passing in AGBP
A. Edge and cluster messaging
GBP can be considered as a method of Kikuchi free energy approximation. It allows in general an arbitrary number of variables to be a clique and includes the clique information into the whole message passing process, while BP only allows site-to-site message passing. Since additional sources of information, such as the clique information, are involved in the message passing process, the search capability is improved for locating the minimum of the energy function.
The approach introduced in [8] comprises two kinds of regions, i.e. single site region and double sites region, and the related messages are named edge message and cluster message, respectively. The message update rules are defined in (4) and (5). Illustrations of the message passing process can be seen in Fig. 1 and Fig. 2.
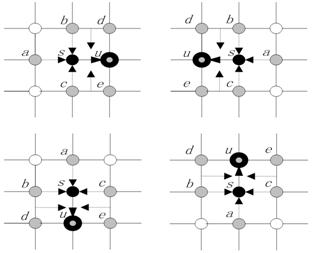
Fig. 1. The edge messages passing from site s to four neighbors.
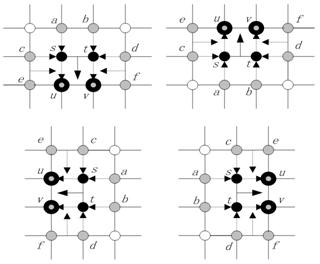
Fig. 2. The cluster messages passing from s, t to u, v.
![]() ?
(4)
?
(4)
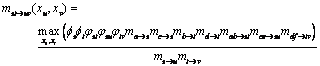 (5)
(5)
where fx is the local evidence of variable x, and jxy is the mutual evidence of variable x and y. Equation (4) describes the edge message sending from a specific site s to site u. Equation (5) describes the cluster message sending from sites s and t to sites u and v.
B. Min-sum messaging
Considering the propagation efficiency, this paper proposes an adaptive strategy to achieve improved performance. Firstly, this paper replaces the message passing scheme in the canonical GBP with a min-sum representation based on (4) and (5), and then a negative logarithm operation is applied. Secondly, to reduce the computational effort for messages, an analog caching method like [11] but defined in the min-sum scheme is employed. The new corresponding message passing rules for the energy function are defined as
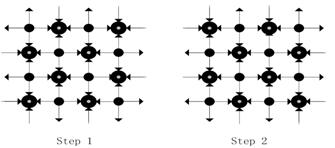
Fig. 3. Chessboard passing for edge messages.
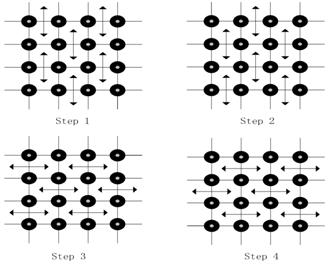
Fig. 4. Chessboard passing for clique messages.
![]() ?
(6)
?
(6)
where
![]() ?(7)
?(7)
and
![]() . ?
(8)
. ?
(8)
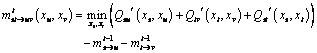 ?9)
?9)
where
![]() , ?10)
, ?10)
![]() , ??11)
, ??11)
and
![]() . (12)
. (12)
where t is the number of iterations and Ps(xs), Qsu' and Qtv' can be treated as cache variables.
The chessboard passing strategy [9] is applied when the message passing process is started. Since GBP has two kinds of messages to update, an extended chessboard passing strategy which updates edge messages and cluster messages in turn is proposed. A diagram of such a process is shown in Figs. 3 and 4. Arrows show the directions of the message passing. The process of message passing is separated into two steps. Small solid nodes are the active nodes which are passing messages to their neighbor nodes. Fig. 4 illustrates that clique message passing consists of two parts, horizontal passing and vertical passing.
After several iterations, the final result is obtained by calculating the belief of each variable. It can be defined as
![]() (13)
(13)
IV. Complexity Reduction
In order to further reduce the complexity of AGBP, this paper introduces two additional strategies for decreasing the exponent number. That is
1. Applying direction set method to reduce the computation complexity of cluster message from O(n4) to O(n3).
2. Using a hierarchical framework and combining with the state space reduction strategy to significantly squeeze the search space, in other words, to decrease n based on the complexity analysis.
First of all, the first strategy and the second strategy will be explained shortly. From (9), when xu and xv are given, the temporal complexity to compute a specific item in the cluster message is O(n2), where n is the dimension of the state space. The majority of the computations is contributed from the first term in the equation, which can be regarded as finding the minimum value in a square lattice where the two axes are s and t, respectively. If all the elements in the lattice are traversed, the temporal complexity is O(n2). Petersen et al. [11] proposed a method to reduce the search space, but it relies heavily on the traverse order. The method proposed in this work is more straightforward. When the direction set method is applied, the temporal complexity becomes O(n), and the total complexity for computing the cluster message is reduced to O(n3).
The direction set method adopted here is also called Powell’s method [14]. It decomposes an N-dimensional (N-D) search problem into several one-dimensional (1D) search processes. Take an example in 2D lattice where a site P has a random initial position and its two orthogonal directions are given. First, P moves to the extreme value position which is found by searching along the first direction among the two initial directions. Second, P moves to another extreme value position by searching along the second direction given by initialization. Third, the first direction is substituted by the second which is set to be a new direction determined by the initial position and the final position after two rounds of searching. Meanwhile, the final position is set to be the new initial position. The three steps are performed in an iterative way until P no longer moves. Fig. 5a illustrates this approach.
(a)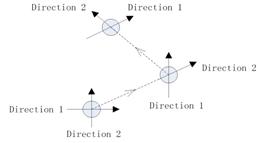
?b)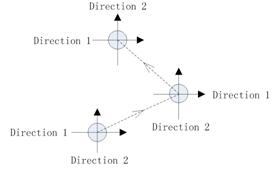
Fig. 5. Two ways of the direction set method. (a) General process of the 2D direction set method. (b) General process of the static direction set method.
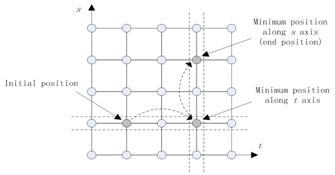
Fig. 6. One iteration in the static direction set method
The general idea of the direction set is challenging because the two directions will become similar in some cases. Since the two arrays of search positions determined by the two directions also become similar, the search capability in this iteration will be reduced and the process is in a high risk of unexpected ceasing. On the other hand, in practice it is hard to search along an arbitrary direction where it requires more computation to determine which sites are occupied. The two directions are set to be static and parallel along each axis (Fig. 5b). This setting not only keeps the orthogonality condition from the beginning to the end, but also makes the implementation easier. Fig. 6 illustrates one iteration in the general process of computing the first part in (9).
Generally, it is more efficient to place the initial position close to the extreme value position. To place it near the minimum value position, an assumption is made that the combination of the independent minimum value positions of s and t is close to the actual minimum value position. In this sense, the initial position (sini, tini) can be given as follows.
![]() ?14)
?14)
![]() (15)
(15)
where Qsu'(xs, xu) and Qtv'(xt, xv) are defined in (10) and (11), which are the independent terms about s and t in (9), respectively.
Through this optimization, the number of accessed positions is decreased from n2 to 2kn, where k is the number of iterations. In our experiments, it is often set as 2 or 3. n is the state space. Since the comparison operation occupies the most computation time, the general complexity becomes 2kn3 while the complexity of brute force search is n4. The efficiency rate is n/(2k). When n is increased, the rate of computation time is also increased.
V. Hierarchical State Space Reduction
In this section, a hierarchical method, called hierarchical state space reduction, is introduced to reduce irrelevant states within a step by step reduction approach. The hierarchical pyramid is constructed similarly as in [8]. The approach collects every four sites to comprise a new site in the coarser level and takes the data cost of the up-left site as the newly replaced site.
Hierarchical structure has an inherent advantage for message based algorithms, e.g. BP and GBP. Message passing in a coarser level means a longer range than that in a finer level. In the proposed approach, the information of a variable can be sent to the variables away from it, not being restricted only to its neighbors. It can largely encourage the information flowing in the whole graph, and make the system converge more quickly. Because message passing is processed at each level separately and the information about the states which are far away from the true state does not much influence the final result. Therefore, the states far away from the true state can be removed, which can also save a large quantity of computations. However, another question might be aroused that the true state could be accidentally smoothed away at a coarser level. To avoid this problem, this paper proposes a state selection approach to selecting a number of most possible states at a finer level.
First, a minimum number of states that each level should maintain is given. The purpose of this setting is to prevent the states from being reduced so fast that the optimization might be over restricted to a small state space and local convergence. This strategy can maintain a space large enough to provide sufficient transferring information and also keep the computation cost at a low level. Furthermore, it is difficult to determine the balance between accuracy and computation cost. Here, to be general, a constant reduction method is proposed by the following definition
![]() (16)
(16)
where G(i) is the minimum number of states at the i-th level, d is the number of states at the coarsest level, L is the number of hierarchical levels, and h is a constant of reduction rate. These parameters are mainly related with the searching range, image resolution, and stereo setup. We may easily find a set of empirical numbers from practical experience for a kind of applications.
After setting the minimum numbers of states at each level, a two-way strategy is used to select the actual amount of states for every variable. First, when the energy of the i-th level comes to converge, beliefs are computed and sorted, and then G(i) states with highest score are chosen to be valid. Second, sort the local evidence and also choose a number of the leading states to be valid. Third, two validation results are combined using the logical “OR?i> operation. This process is shown in Fig. 7. In the i-th level, all five states are valid. Through two kinds of state selection process, the third state is set to be invalid in the (i+1)-th level.
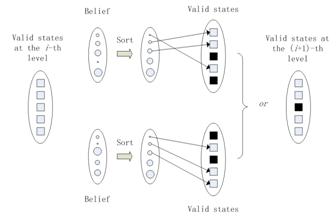
Fig. 7. The state selection process. White or black squares represent valid or invalid states. Bigger circles in the belief vector and local evidence vector stand for lower possibility to be the true state. In this example, the valid states of the current site at the i-th level is 5, and G (i+1) is 3.
This state selection method has several merits. First, the best states selected by beliefs can be passed down to next level as a result from the coarser level. Second, some wrongly invalidated states are reserved according to their superior local evidences.
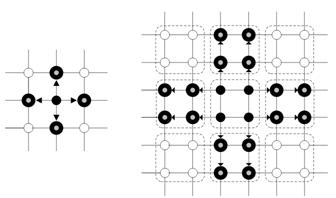
Fig. 8. Edge message inheritance. LEFT: coarse level. RIGHT: fine level.
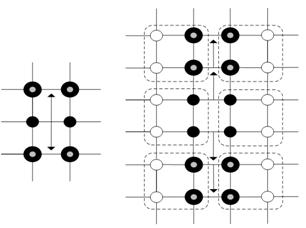
(a) Vertical clique message inheritance. LEFT: coarse level. RIGHT: fine level.
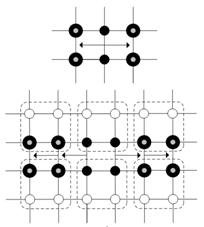
(b) Horizontal clique message inheritance. UP: coarse level. DOWN: fine level.
Fig. 9. Clique message inheritance
After setting the valid states in the next level, the related messages should also be passed over. Since the number of valid states is changed, the item related to the invalid states in messages should be abandoned so that the inherited messages for each variable at the finer level are different. This inheriting strategy is different from that in [9]. In this proposed method, a message inherited from a coarser level reaches two sites away from it at a finer level. It can increase the restriction length from the coarser level and help useful information flowing. The corresponding message inheriting processes are illustrated in Figs. 8 and 9. The main motivation of this approach is to pass a message to all the related variables in a finer level and thus it can avoid information loss by the greatest extent. In other words, make the influence from the result of the coarser level to the optimization of the next level the furthest.
VI. Experiments
 Some practical experiments
are carried out to test the AGBP method in this study. One of the typical
applications is for stereo matching, which is a classical problem in computer
vision. The purpose is to find a dense correspondence between two images which are
captured in two different viewpoints. To simplify this process, the images are transformed
to guarantee that two matched points only have a horizontal displacement, and
then the result also called depth map can be coded in a one-channel image. The
grey value of a pixel represents the horizontal displacement of its matched
pixel. There are a set of standardized image pairs to test stereo matching
algorithms available on the web [15]. In the
experiments on these image pairs, we use a set of parameters as: T = 30.0 and l= 0.87 in the data cost term, K = 10.0 in the smooth cost term, and 5 for the number of
levels from the coarsest to the finest. d and h in G depend on disparity range
of specific image pair To make the data cost more smooth, the source image
pairs are initially filtered by a 3?/span>3 Gaussian smooth kernel with s= 0.7.
Some practical experiments
are carried out to test the AGBP method in this study. One of the typical
applications is for stereo matching, which is a classical problem in computer
vision. The purpose is to find a dense correspondence between two images which are
captured in two different viewpoints. To simplify this process, the images are transformed
to guarantee that two matched points only have a horizontal displacement, and
then the result also called depth map can be coded in a one-channel image. The
grey value of a pixel represents the horizontal displacement of its matched
pixel. There are a set of standardized image pairs to test stereo matching
algorithms available on the web [15]. In the
experiments on these image pairs, we use a set of parameters as: T = 30.0 and l= 0.87 in the data cost term, K = 10.0 in the smooth cost term, and 5 for the number of
levels from the coarsest to the finest. d and h in G depend on disparity range
of specific image pair To make the data cost more smooth, the source image
pairs are initially filtered by a 3?/span>3 Gaussian smooth kernel with s= 0.7.
To show the improved efficiency as well as the accuracy of the proposed method, the evaluation presented here is mainly among three algorithms, i.e. efficient BP [9], canonical GBP [11], and the proposed AGBP. The efficient BP, up to now, is the first and the only global algorithm that has achieved real-time demand in stereo matching using a parallel implementation [10]. Its efficiency and accuracy can be considered as a milestone of such message based algorithms. Although the implementation of our proposed method is by means of single thread and therefore it is not reasonable to compare it with [10]. However, we believe our approach has some favorable features in the final results from a message based point of view. The experiments of canonical GBP algorithm carried out in this research are aimed to show the typical accuracy of this kind of methods for comparison. In all of the experiments here, the same test set of image pairs provided by Scharstein et. al. [15] are used. The performance was tested by a commodity CPU with 2.13 GHz and 2G DRAM.
TABLE I. EVALUATION OF EFFICIENCY AND CONVERGENCE
|
|
Algorithm |
Duration |
Convergence energy |
Acceleration rate |
|
GBP |
Canonical GBP |
35482.5 s (?/span>10 hours) |
406013 |
1.0 (Standard) |
|
GBP+ |
+ caching |
5198.8 s (?/span>1.5 hours) |
406013 |
6.83 times |
|
GBP++ |
+ caching + direction set |
1969.815 s (?/span>30 min) |
409994 |
18.01 times |
|
AGBP |
+ caching + direction set + hierarchical state space reduction |
168.231 s (?/span>2 min) |
381793 |
210.92 times |
Among the three main optimization strategies, i.e. caching, direction set and hierarchical state space reduction, caching is a lossless method while direction set and hierarchical state space reduction may cause loss of accuracy. The ultimate purpose of the proposed strategies is to improve the efficiency of canonical GBP as well as keep it in a good accuracy. As shown in Table I, the execution time which combines the three strategies can be extensively reduced, while the convergence energy rises a little bit due to some side effects. The canonical GBP augmented with all those three strategies can achieve about 200 times of the speed rate. It should be noted that the accelerating rates are related with the size of the MRFs and the range of the state space, not the image context. The experiments were tested with “Tsukuba?(384 ?/span> 288 size) and “Venus?434 ?/span> 383 size). The ranges of the state space (d in G) are 16 and 20, and the reduction constants (h in G) are 3 and 4.
Furthermore, since AGBP is an approach based on message passing, it can also be implemented in a parallel way. Attributing to the high efficiency of a parallel computing architecture, e.g. compute unified device architecture (CUDA), it is found that the proposed method can execute much faster, even possibly for real-time applications.
Table II gives the accuracy evaluation of “Tsukuba?of three different algorithms. Since the proposed method uses a hierarchical strategy to encourage the information flowing, the accuracy is higher than that of canonical GBP. Comparing it with the accuracy of efficient BP, the proposed method yields a similar level. According to the results of [11], the acceleration rate is very small when the number of labels is below 64, i.e. from 0.6 to 5 times of the Standard speed. The rate goes up to 26 when the number of labels increases to 256. In stereo matching, however, the number of labels is usually from 10 to 30. By comparison, the proposed AGBP in this paper can always reach at about 200 times of acceleration.
Except for the errors of the results, another reasonable assessment criterion is to take a close look at the depth maps and analyze their visual quality. The comparison between the proposed method and canonical GBP is carefully assessed. Fig. 10 lists the results based on three test images which are provided by [15]. From the results, it’s noticeable that each method has its own merits. If we concern some conspicuous feature points, the canonical GBP makes a better result than the proposed method. However in some other areas, like the massive noise pervaded in the depth maps, since the proposed method uses a hierarchical structure to send information over a wider range, the surface becomes more accurate than that of canonical GBP.
TABLE II. EVALUATION OF ACCURACY (%)
|
|
e ?/span>[0, 1] |
e ?/span> (1, 2] |
e ?/span> (2, 3] |
e > 3 pixels |
|
Efficient BP |
89.2 |
7.0 |
0.3 |
3.5 |
|
Canonical GBP |
79.1 |
13.2 |
2.8 |
4.9 |
|
AGBP |
86.5 |
8.1 |
1.8 |
3.6 |
On the other hand, through the comparison between the proposed method and efficient BP, it is noticeable that efficient BP tends to get a fronto-parallel result which makes the surface over smooth and results in a layered effect, although it can still achieve a good result on objects?boundary. In the contrary, the proposed method does not have the drawback of layered effects like that caused by efficient BP, but the depth map becomes blurred at the boundaries and some noises cannot be eliminated. In fact, although a layered result can reach a lower energy, it cannot always be a better description of the outdoor scenes. Since the test images are mostly composed of plane-like objects, the implied fronto-parallel assumption always gives the least cost in these situations. However, comparing with the proposed method, it causes some over sharp edges and obvious layered effect surely which are not realistic and visual favorite.
Table III gives the specific temporal analysis in iterations. The massive computation of canonical GBP is split into several small scale iterations in the proposed method. Since the canonical GBP carries the temporal complexity of O(n4), the duration of these small scale iterations is sharply reduced. Taking a close look at the time costs at each level in the proposed method, the durations are still rising in times. The reason is that the parameter G is still very large at finer levels. However, if the labels are reduced more rapidly in G for the purpose of speed, the state space maybe shrinks too quickly so that the results could be worse. Therefore, the tradeoff between the speed and the accuracy is paradoxical. The settings used in our experiments have reached a good balance.
TABLE III. EXECUTION TIME IN ITERATIONS (ms)
|
Iterations |
Proposed AGBP |
Canonical GBP |
||||
|
Level 5 |
Level 4 |
Level 3 |
Level 2 |
Level 1 |
||
|
1 |
982 |
2808 |
5772 |
11076 |
17379 |
7299?/span>103 |
|
2 |
889 |
2808 |
5756 |
11170 |
17706 |
7098?/span>103 |
|
3 |
874 |
2761 |
5647 |
11029 |
17347 |
7177?/span>103 |
|
4 |
858 |
2761 |
5632 |
10983 |
17097 |
6926?/span>103 |
|
5 |
|
|
|
10998 |
|
6980?/span>103 |
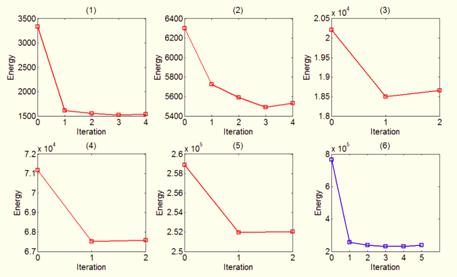
Fig. 11. The energy function in every iteration of the “Tsukuba?image pair. (1) to (5) the energy curves at each level. (6) the energy curve of canonical GBP.
Figure 11 shows the energy variation in canonical GBP and each level of the proposed method. From those curves, it can be found that the energy of canonical GBP decreases rapidly in the first iteration. In later iterations, the energy changes slowly. In the contrary, the energy in our proposed method decreases evenly in each iteration at each level, which can be treated as a space selection at different scales. The major effect of this selection process is to get a better convergence, while canonical GBP often trends to trap in a local minimum near the initial position.
VII. Conclusion
The inference problem is very important in statistical physics as well as in many other fields. This paper especially solves such a problem in large scale MRFs using AGBP. A min-sum scheme is invented for the message computing process in AGBP. Furthermore, two other strategies are proposed for improving the efficiency, i.e. the direction set and hierarchical state space reduction. Using the direction set method, the complex of computing the cluster message can be reduced from O(n4) to O(n3), and using hierarchical state space reduction, an extra acceleration rate of n/(2k) can be achieved in theory, where n is the state space and k is the number of iterations. Therefore, when compared with canonical GBP, the proposed AGBP can improve the efficiency up to 200 times for a typical field size of 300?/span>300 in the problem of stereo matching.
References
[1] A. Sinha, S. Gupta, "A Fast Nonparametric Noncausal MRF-Based Texture Synthesis Scheme Using a Novel FKDE Algorithm," IEEE Trans. Image Processing, vol.19, no.3, pp.561-572, March 2010.
[2] D. Bruckner, R. Velik, "Behavior Learning in Dwelling Environments With Hidden Markov Models," IEEE Trans. Industrial Electronics, vol.57, no.11, pp.3653-3660, Nov. 2010
[3] C. Wolf, "Document Ink Bleed-Through Removal with Two Hidden Markov Random Fields and a Single Observation Field," IEEE Trans. Pattern Analysis and Machine Intelligence, vol.32, no.3, pp.431-447, March 2010.
[4] S. Zaidi, S. Aviyente, et al., "Prognosis of Gear Failures in DC Starter Motors Using Hidden Markov Models," IEEE Trans. Industrial Electronics, vol. 58, no. 5, pp. 1695 ?1706, 2011.
[5] L. Zhu, Y. Chen, A. Yuille, "Unsupervised Learning of Probabilistic Grammar-Markov Models for Object Categories," IEEE Trans. Pattern Analysis and Machine Intelligence, vol.31, no.1, pp.114-128, Jan. 2009.
[6] J. Goldberger and H. Kfir, "Serial Schedules for Belief-Propagation: Analysis of Convergence Time," IEEE Trans. Information Theory, vol.54, no.3, pp.1316-1319, March 2008.
[7] J. S. Yedidia, W. T. Freeman and Y. Weiss, “Generalized belief propagation? Neural Information Processing Systems, pp: 689?95, 2000.
[8] J. S. Yedidia, W. T. Freeman and Y. Weiss, “Constructing free-energy approximations and generalized belief propagation algorithms? IEEE Trans. Information Theory, vol. 51, no. 7, 2005.
[9] P. Felzenszwalb and D. Huttenlocher, “Efficient belief propagation for early vision? Int. J. Computer Vision, vol. 70, no. 1, pp: 41-54, 2006.
[10] Qingxiong Yang, Liang Wang, Ruigang Yang, etc., "Stereo Matching with Color-Weighted Correlation, Hierarchical Belief Propagation, and Occlusion Handling," IEEE Trans. Pattern Analysis and Machine Intelligence, vol.31, no.3, pp.492-504, March 2009.
[11] K. Petersen, J. Fehr and H. Burkhardt, “fast generalized belief propagation for MAP estimation on 2D and 3D grid-like markov random fields? 30th Deutsche-Arbeitsgemeinschaft-fur-Mustererkennung Symp. Pattern Recognition, Munich, Germany, pp. 10-13, June 2008.
[12] S.Y. Chen, H. Tong, Z.J. Wang, et al., "Improved Generalized Belief Propagation for Vision Processing", Mathematical Problems in Engineering, AID: 416963, 2011.
[13] B.S.R. Armstrong, S.K.P. Veettil, "Soft Synchronization: Synchronization for Network-Connected Machine Vision Systems," IEEE Trans. Industrial Informatics, vol.3, no.4, pp.263-274, Nov. 2007.
[14] W. H. Press, S. A. Teukolsky, W. T. Vetterling and B. P. Flannery, “Numerical Reciples in C? Cambridge University Press, 1992.
[15] D. Scharstein and R. Szeliski, "Middlebury Stereo Vision Research Page", http://vision.middlebury.edu/stereo/eval/, 2008.
[16] Youngchul Sung, H.V. Poor, Heejung Yu, "How Much Information Can One Get From a Wireless Ad Hoc Sensor Network Over a Correlated Random Field?," IEEE Trans. Information Theory, vol.55, no.6, pp.2827-2847, June 2009.
[17] Myung Jin Choi, V. Chandrasekaran, A.S. Willsky, "Gaussian Multiresolution Models: Exploiting Sparse Markov and Covariance Structure," IEEE Trans. Signal Processing, vol.58, no.3, pp.1012-1024, March 2010.
[18] E.I. Athanasiadis, D.A. Cavouras, et al., "Segmentation of Complementary DNA Microarray Images by Wavelet-Based Markov Random Field Model," IEEE Trans. Information Technology in Biomedicine, vol.13, no.6, pp.1068-1074, Nov. 2009.
[19] P.P. Gajjar, M.V. Joshi, "New Learning Based Super-Resolution: Use of DWT and IGMRF Prior," IEEE Trans. Image Processing, vol.19, no.5, pp.1201-1213, May 2010.
[20] Chih-Yuan Chung, H.H. Chen, "Video Object Extraction via MRF-Based Contour Tracking," IEEE Trans. Circuits and Systems for Video Technology, vol.20, no.1, pp.149-155, Jan. 2010.
[21] O. Dikmen, A.T. Cemgil, "Gamma Markov Random Fields for Audio Source Modeling," IEEE Trans. Audio, Speech, and Language Processing, vol.18, no.3, pp.589-601, March 2010.
[22] Jiejie Zhu, Liang Wang, et al., "Spatial-Temporal Fusion for High Accuracy Depth Maps Using Dynamic MRFs," IEEE Trans. Pattern Analysis and Machine Intelligence, vol.32, no.5, pp.899-909, May 2010.
[23] M. Soccorsi, D. Gleich, M. Datcu, "Huber–Markov Model for Complex SAR Image Restoration," IEEE Geoscience and Remote Sensing Letters, vol.7, no.1, pp.63-67, Jan. 2010.
[24] I. Morgan and H. Liu, "Predicting Future States With n -Dimensional Markov Chains for Fault Diagnosis," IEEE Trans. Industrial Electronics, vol.56, no.5, pp.1774-1781, May 2009.
 Shengyong Chen (M?1–SM?0) received the
Ph.D. degree in computer vision from City University of Hong Kong, Hong Kong,
in 2003. He joined Zhejiang
University of Technology, China, in Feb. 2004 where he is currently a Professor
in the Department of Computer Science. From Aug. 2006 to Aug. 2007, he received a
fellowship from the Alexander von Humboldt Foundation of Germany and worked at University of Hamburg, Germany. From Sep. 2008 to Aug. 2009, he worked as a
visiting professor at Imperial College, London, U.K. His research interests
include computer vision, robotics, 3D object modeling, and image analysis. Dr. Chen is a senior member of
IEEE and a committee member of IET Shanghai Branch. He has published over 100
scientific papers in international journals and conferences.
Shengyong Chen (M?1–SM?0) received the
Ph.D. degree in computer vision from City University of Hong Kong, Hong Kong,
in 2003. He joined Zhejiang
University of Technology, China, in Feb. 2004 where he is currently a Professor
in the Department of Computer Science. From Aug. 2006 to Aug. 2007, he received a
fellowship from the Alexander von Humboldt Foundation of Germany and worked at University of Hamburg, Germany. From Sep. 2008 to Aug. 2009, he worked as a
visiting professor at Imperial College, London, U.K. His research interests
include computer vision, robotics, 3D object modeling, and image analysis. Dr. Chen is a senior member of
IEEE and a committee member of IET Shanghai Branch. He has published over 100
scientific papers in international journals and conferences.
 Zhongjie Wang received the BSc and
MSc degrees in Pattern Recognition and Machine Intelligence from the College of Information Engineering, Zhejiang University of Technology in 2007 and 2010, respectively,
under the supervision of Dr. Shengyong Chen. He is currently a visiting scholar
in Max-Planck-Institut für Informatik (MPII), Campus E1 4, 66123 Saarbruecken , Germany, under the supervision of Dr. Thorsten Thormaelen. During his study,
he joined a National Natural Science Foundation of China (NSFC),
"Purposive Perception Planning Method for 3D Target Modeling",
completed his thesis on "Stereo Matching for 3D Computer Vision", and
applied two patents.
Zhongjie Wang received the BSc and
MSc degrees in Pattern Recognition and Machine Intelligence from the College of Information Engineering, Zhejiang University of Technology in 2007 and 2010, respectively,
under the supervision of Dr. Shengyong Chen. He is currently a visiting scholar
in Max-Planck-Institut für Informatik (MPII), Campus E1 4, 66123 Saarbruecken , Germany, under the supervision of Dr. Thorsten Thormaelen. During his study,
he joined a National Natural Science Foundation of China (NSFC),
"Purposive Perception Planning Method for 3D Target Modeling",
completed his thesis on "Stereo Matching for 3D Computer Vision", and
applied two patents.